| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 압축권한
- 파일이 너무 커서 안들어감
- mybatis
- 팰린드롬개수
- c드라이브에서 압축
- 로또의 최고 순위와 처저 순위
- 6tunnel
- PostgreSQL
- 프로그래머스
- 신고결과받기
- db
- programmers
- Linux
- Docker
- 관리자권한 문제
- 특정ip차단
- 폴더압축 권한문제
- LV1
- 특정ip접근
- 도커
- java
- 데이터넘기기
- on conflict
- ipv6->ipv4
- usb 포맷시스템
- c드라이브에서 압축 안될때
- 방화벽정책
- 2022 KAKAO BLIND RECRUITMENT
- usb 공간있는데
- maven-install
- Today
- Total
개발 기록일지
Selenium 활용하기 본문
이번에 회사 업무로 Selenium 으로 크롤링을 활용해서 프로그램을 만들일이 생겼다.
그래서 만드면서 사용한 selenium 소스를 정리해봄
Chromedriver driver;
ChromeOptions options;
String DRIVER_ID
String DRIVER_PATH
String base_url
===============================================
DRIVER_ID = "webdriver.chrome.driver";
DRIVER_PATH = "chromedriver.exe가 있는 경로";
base_url = "접속하려는 주소";
System.setProperty(DRIVER_ID, DRIVER_PATH);
options=new ChromeOptions();
options.addArguments("headless");
driver=new ChromeDriver(options);
driver.get(base_url);일단 Selenium 사용하려면 chromedriver 를 자신의 chrome 버젼에 맞게 다운받아서 원하는 경로에 위치시켜야 한다.
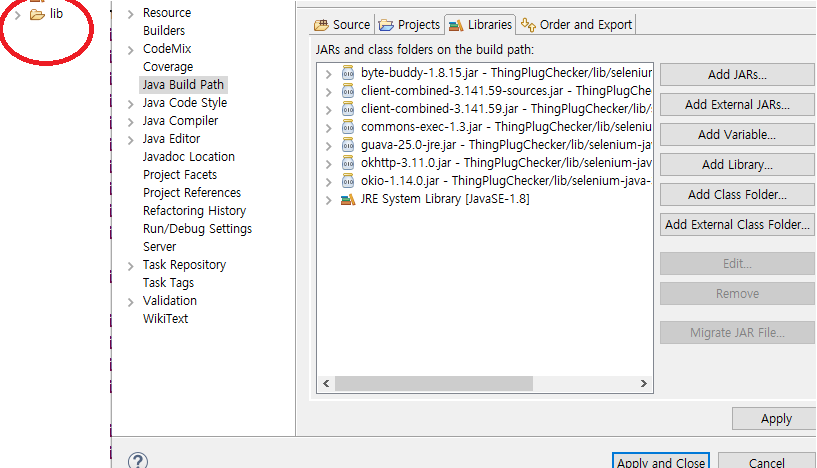
Selenium 라이브러리도 다운받고 프로젝트 아래다가 저렇게 lib 폴더 만들어서 buildpath 추가함
Selenium 은 chromedriver 를 실행시켜서 자동제어를 하는것이 특징인데
이 chromedriver가 백그라운드로 실행되도록, 내 눈앞에서 내가 만든 이벤트들(페이지 이동하고 클릭하고) 이 보여지는 것이 싫으면 위와 같이 ChromeOptions 객체의 options.addArguments("headless")를 사용하면 된다.
접속한 페이지에서 메뉴를 누르거나 어떤 버튼을 누르려면 거기에 해당하는 WebElement를 따야된다.
크롤링 하려는 페이지를 접속해 F12를 누르면

이런식으로 화면에서 해당 요소가 위치한 값의 CssSelector,xpath 등의 정보를 따올수가 있다.
그래서 이거를
WebElement btn=driver.findElement(By.cssSelector("#tinymce > p:nth-child(13)"));
btn.click();
이런식으로 변수에 담아서 click을 통해 동작시킬 수 있다.
만약 로그인하는 경우에는 ID/PW 입력칸의 element 변수에 .setText("asd");
이런식으로 값을 집어넣으면 된다.
text_box_id.setText("Tistory");
text_box_pw.setText("Tistory");
text_box_login_btn.click();
** 이렇게 클릭하고 해당 화면에 나오는 데이터를 긁어올텐데 문제는 해당 페이지를 불러오기전에 동작을 실행시키면
NoSuchElement 라는 예외가 무수히 발생할 것이다**
이를 해결하기 위해 Selenium라이브러리에서 제공하는 WebDriverWait를 사용하면 된다.
WebDriverWait wait=new WebDriverWait(driver, 10);
WebElement btn_login_first=wait.until(ExpectedConditions.visibilityOfElementLocated(By.id("log_in")));
btn_login_first.click();내가 10초의 타임아웃을 지정해주고 최대 10초까지 해당페이지에 값들이 로딩될때까지 기다리는거다. 그 안에 처리되면 바로 처리되는거고 10초까지 기다렸다가 안되면 예외가 생기는거다.
그러면 내가 어떤 동작을 하도록 지정했을때 그걸 못찾아서 생기는 예외는 사라진다.
*참고로 driver.manage().timouts().implicitlyWait(5,TimeUnit.SECONDS); 이렇게 암시적으로 처리하는 방법도 있다.
무조건 5초로 설정하는거다.
보통 findElement 로 찾기 전에 어떤 동작들을 하고 다음 동작 넘어갈때 Thread.sleep(3000); 이런식으로 처리하는 게 인터넷이 많은데 이 방법은 별로 좋지않다. 라고 stackoverflow 형님들이 말씀하시더라
++그리고 element를 가져올때 xpath 보다는 cssSelecotor 를 copy하는게 더 속도가 빠르다고함.
사실 Selenium 사용하면 element 변수에 담고 click하고 이동하고 이게 다다. 그외에는 자신이 만든 소스로 긁어온것들 만지면 되는일.
Selenium 이용해서 크롤링하는 것은 내가 인터넷 창 켜서 클릭하고 하는일을 chromeDriver가 내가 지정한 순서대로 대신 수행해주는 거다. 사실 크롤링이라고 하기도 뭐하지만..